고정 헤더 영역
상세 컨텐츠
본문
728x90
거의 다 INNER JOIN이라고 함
자르면 좋은점 : 중복 제거
-> 실제 저장되는 데이터량 감소


식별 KEY ---------------- 참조하는 형태 (참조 KEY/외래 KEY를 참조를 위해 가지고 있음)
ㅡㅡㅡㅡㅡ
만약 MEMBER, NOTICE 합치고 싶다면
1. 부모 찾기 (NOTICE가 WRTIER_ID를 참조 KEY로 가지고 있음)

'참조 키 비교를 통한' JOIN이 이렇게 이루어진다.
* INNER JOIN의 특징 *
- 참조되고 있는 녀석, 참조하고 있는 녀석 '만' 정보가 나옴
MEMBER 25개 NOTICE 45개
-> JOIN 후 왜 28개가 됐을까

Q. JOIN 하면 몇 개가 생길까?
부모가 4개지만, 실제 참조되고 있는건 1개
관련 있는 것 : INNER
관련 없는 것 : OUTER
INNER JOIN하면 INNER들만 합치는 것


-> 3개
JOIN 종류가 많은데 INNER JOIN이 기본이다!
ㅡㅡㅡㅡㅡ
JOIN했을 때 결과 수를 맞춰보자
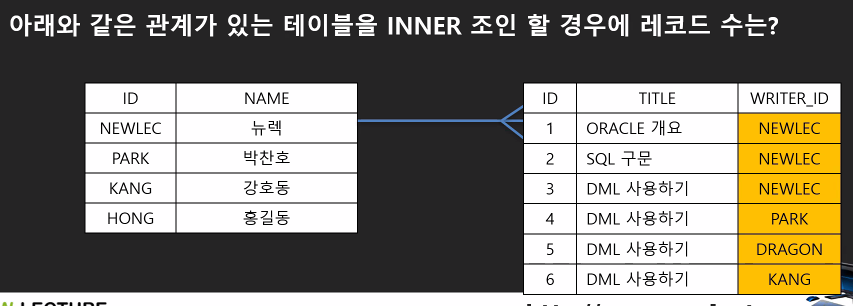
-> 5개
(자식 테이블에서 INNER가 몇 개인지 세면 됨)
(이거를 참고해서 -> 부모를 고치는거니까)
OUTER JOIN
= OUTER도 포함시키는 JOIN
근데 부모, 자식 다 OUTER가 있을 수도 있는데

둘 다 -> FULL OUTER
오른쪽, 왼쪽
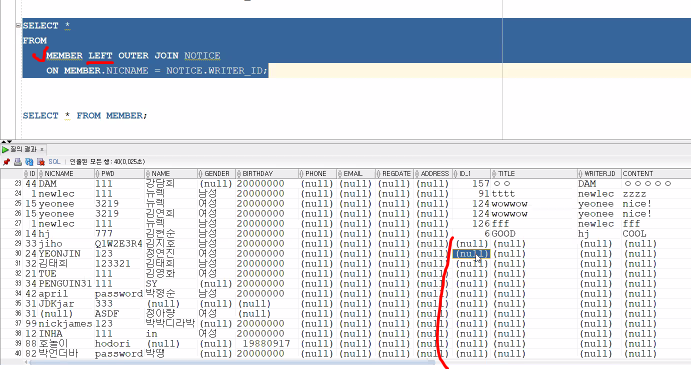

애는 RIGHT, 즉 NOTICE 쪽을 (이건 가변적임) OUTER 껴주겠다는거니까
NOTICE의 WRITER_ID는 다 차 있는 반면, MEMBER의 아랫 부분은 NICNAME은 NULL
INNER JOIN에서의 INNER는 생략 가능 (기본이기에)
OUTER JOIN에서는 RIGHT, LEFT... 이런거 쓰면 OUTER 생략 가능
ㅡㅡㅡㅡㅡ
* JOIN할 때 문제 *

-> 6개



-> 5개 (INNER 3개와 + 오른쪽의 OUTER 2개)
ㅡㅡㅡㅡㅡ
FULL OUTER JOIN

-> 8개
(INNER 3개 + LEFT OUTER 3개 + RIGHT OUTER 2개)

" Join 너~무 중요합니다. "
선택해서 JOIN 가능


-> 이러면 AMBIGUOUS 오류 메시지 남
-> 애매하지 않게 쿼리를 만들어야 함

이렇게 원하는 것만 뽑아낼 때는 앞에 테이블 명을 써준다.
FROM절 먼저 실행
/ 그 다음 SELECT
불편한거 해결하기 위해 이름을 줄여 쓴다.
테이블에다가 별칭을 만든다 (FROM절이 먼저 실행되기에 이게 가능!)


현실은 OUTER 조인을 더 많이 쓴다.
INNER JOIN의 맹점에 대해 알아보자.

FROM 절이 가장 먼저 일어나고
GROUP BY
그리고 SELECT
'ID, NAME 별로' COUNT를 세는 것
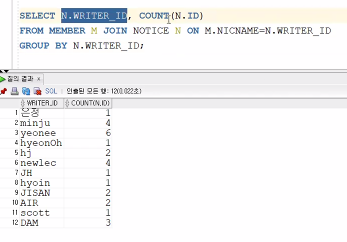
ID, NICNAME, NAME만 NOTICE ID로 집계를 하고 싶은 것
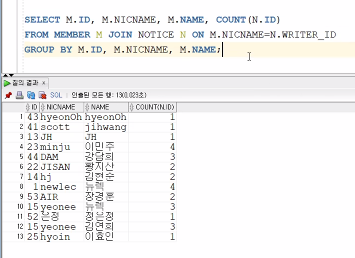
★ 이거! ★
Q. 이상한 점
-> 다 글을 쓴 사람만 나옴
글을 안 썼으면 0이라고도 나와야 하는데, INNER JOIN을 해버리면 회원 목록이 사라지는 것
JOIN은 한 쪽이 '주인공'인 것
-> 한 쪽이 주인공이면 OUTER도 나오게 하자!
(이 문제에서는 회원 목록은 다 나와야 하는 것)

이렇게!
ㅡㅡㅡㅡㅡ 3개를 JOIN해보자
Q. 쿼리 확장 문제.
1. NOTICE - ID, TITLE, WRITER_ID를 출력하고 싶음
SELECT ID, TITLE, WRITER_ID FROM NOTICE;

2. MEMBER - NAME을 WRITER_NAME로 1번과 함께 출력하고 싶음


이거 안 보고 다시 해보기
-> N.WRITER_ID = M.NICNAME은 이게 같다는게 아니라 '같은 것만' JOIN하겠다는 조건임(!)
3. 댓글 개수 추가하고 싶음

HINT) 옆에것들을 다 GROUP BY 해서
HINT) 3개 JOIN하는 법
안에 JOIN한걸 결과물로 보고 !
그 아래 또 JOIN "COMMENT" ON ...


위에는 C.ID로 다들 함
집계(COUNT)가 들어가면 '전체'를 하는건지, '별' 하는건지 꼭 구분해야함
-> 여기서는 지금 SELECT 뒤에 있는 것들 '별' 집계해달라는 거니까 이거 복사해서
맨 아래 GROUP BY 절에다가 두면 됨
Q. "COMMENT" 이유
-> 예약된 명령어인 경우는 "" (비 : 예를 들어 테이블명이 JOIN이면 "JOIN" 이렇게)
// 우리가 해야할 기본적인 난이도
"여러 번 연습해야 합니다."
1. FROM에서
(1) 제일 먼저 JOIN - 공지사항이 주인공 + 멤버 데이터 합침
(2) COMMENT도 합치자하면 또 들어옴
2. GROUP BY -> 그럼 줄어듦
3. '게시글별'
NOTICE 부모가 COMMENT 자식을 가진다고 생각을 해보자.
부모 : 자식 관계는 1:多지. (한 글에 여러개의 댓글을 쓸 수 있다고 생각하면 이해하기 더 쉽지)
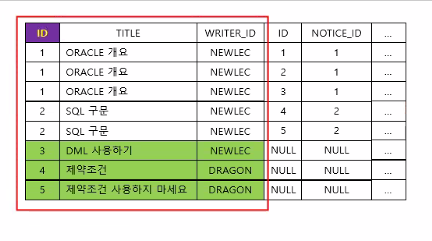
그런데 문제는 '합쳐질때'.
댓글을 많이 쓴 만큼 부모의 데이터가 중복되게 됨 (위에 보면 NOTICE_ID 1에 부모 데이터 같은 게 3개가 들어감)
"자식과 합쳐지는 부모는 복제되어질 수밖에 없다."
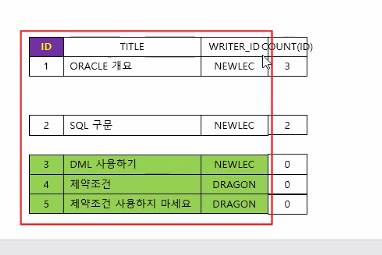
주인공은 부모인데, 주인공을 망가뜨리면서까지 합치는 JOIN은 하면 안 됨
-> 하지만 '집계'(COUNT)는 가능
집계는 중복되지 않게 합쳐주기 때문임
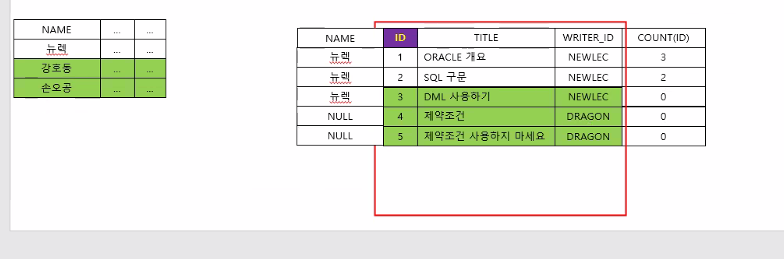
cf) 반대로 자식을 주인공으로! (자식도 주인공이 될 수 있는거겠지?) 부모를 합쳐주는건 상관 없음
주인공의 데이터는 온전하기 때문에
Q. 최신글 10개만 조회하기
HINT ) 정렬, PAGING을 위해 ROWNUM 이용
CONTENT는 목록으로 나타내지 않는다. (메모리상)
-> 에러남 (너무 큰 자료라)
다 채워서 불러와야함

그리고 페이징 위해 WHERE절도 추가해야하지

이유를 알기 위해 ROWNUM을 추가해보자

ROWNUM이 엄청 꼬여있구나~
PAGING을 가능하게 하기 위해 서브 쿼리를 썼었음
-> 3번 중첩해야함... 끔찍...
단순화 시키자!
다음 시간에 규? 뷰?에 대해서 얘기해보자.

728x90
반응형
'수업 일지 > Oracle DBMS' 카테고리의 다른 글
| 58일차. DB 11 - 모델링 (개념설계, 논리설계) (0) | 2021.05.12 |
|---|---|
| 57일차. DB 11 - VIEW, SELF JOIN, 서브 쿼리로 간단하게 표현하기 (0) | 2021.05.11 |
| 55일차. DB 9 - JOIN (INTRO) (0) | 2021.05.07 |
| Oracle 기본 함수 정리 (0) | 2021.04.30 |
| 51일차. DB 8 - ORDER BY, GROUP BY, HAVING, 서브쿼리 (페이징) (1) | 2021.04.30 |




